
Laboratories such as this one in New Delhi, India, are sequencing the genomes of coronavirus samples, racing to detect the Omicron variant.Credit: T. Narayan/Bloomberg via Getty
Researchers are racing to detect Omicron, the latest SARS-CoV-2 variant of concern, by sequencing the genomes of coronaviruses infecting people. But surveillance through genomic sequencing can be slow and patchy, complicating the picture of how and where Omicron spreads.
One positive development is that researchers are sequencing more SARS-CoV-2 genomes than ever before. This is what enabled them to notice Omicron relatively swiftly. Last April — about 16 months into the pandemic — an online database belonging to the GISAID data-science initiative contained one million SARS-CoV-2 genomic sequences. Since then, researchers have submitted another five million sequences to GISAID in about eight months — a nearly tenfold rate increase (see ‘Genome explosion’). “We are in much better shape to find Omicron or any other emerging variant now,” says Kelly Wroblewski, director of infectious diseases at the Association of Public Health Laboratories in Silver Spring, Maryland.
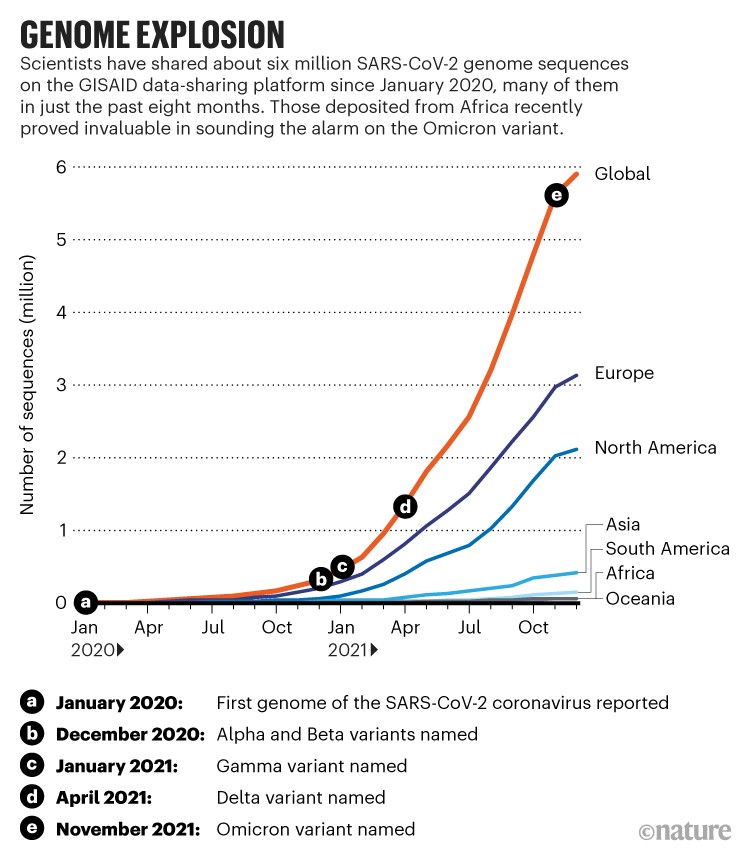
Source: GISAID
Yet researchers warn that there are still troubling gaps in sequencing data that make any interpretation of a variant’s movement fraught. “The numbers are complex, and there are so many caveats,” Wroblewski says. For one, some countries don’t have the laboratory capacity to sequence pathogen genomes, so it might look like those places have no variants, when in fact the mutated viruses are spreading under the radar.
Sequencing rates vary within countries, as well, yielding an uneven picture of how a variant is spreading within a nation’s borders. For instance, 10 US states have sequenced less than 2% of the coronaviruses infecting people who tested positive for COVID-19 in those states in the past month, according to sequences posted at GISAID. By contrast, Wyoming, Colorado and Vermont sequenced more than 10% of their positive cases over the same time frame (see ‘States of surveillance’).
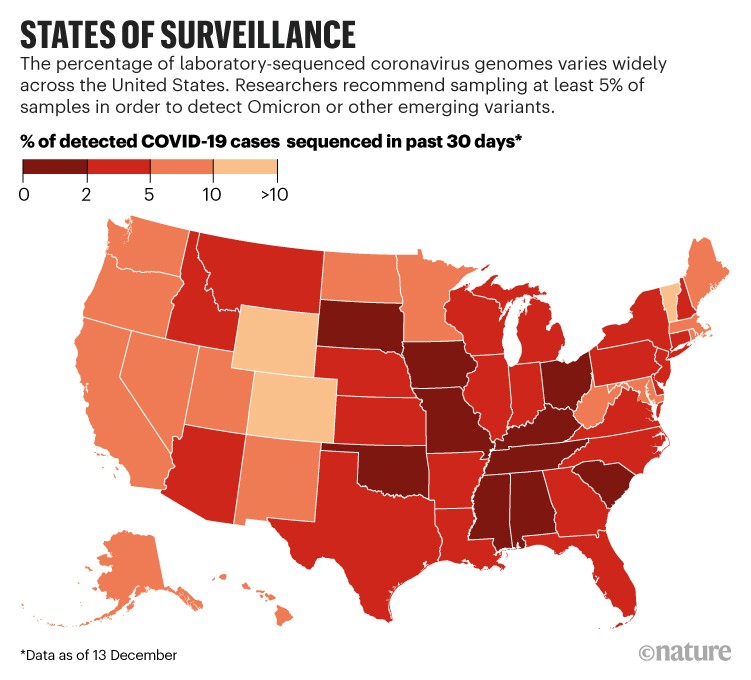
Sources: GISAID and the Pandemic Prevention Institute at the Rockefeller Foundation
But even if a location is sequencing many of its positive cases, variants could still slip by if testing is poor or biased. “It’s easy to sequence 100% of your cases if you only test a few people to begin with,” explains Jennifer Nuzzo, an epidemiologist at Johns Hopkins University in Baltimore, Maryland. For example, some countries mainly test international travelers. Even if they sequence all of those samples, they might miss a concerning variant that is circulating domestically.
Minding the data gap
Faced with such surveillance challenges, epidemiologist Sam Scarpino and his colleagues at the Pandemic Prevention Institute at the Rockefeller Foundation in Washington DC have been seeking new ways to understand the spread of variants. One method is to use a model they’ve developed to estimate how prevalent Omicron would need to be in a given locality before it would be detected by public-health officials, given the state of testing and sequencing in that particular area. Omicron would need to be relatively common for researchers to identify it in a place with little surveillance, for example.
The team is also constructing timelines using Omicron reports that are uploaded to GISAID each day, to draw a clearer picture of detection. They order sequences on the basis of the dates that the samples were collected — rather than when they appear online in the database. Timing can be confusing because weeks might pass between when a person tests positive for the coronavirus and when a sample is shipped to a genomics lab, sequenced and then reported online and to authorities. For example, according to data that was on GISAID as of 9 December, the first person known to have been infected with Omicron was sampled in South Africa on 8 November, about three weeks before the viral sequence for that particular sample was posted online — and nearly two weeks before South Africa’s first report of Omicron. Since then, more data have streamed in, and a new sequence of Omicron dates back to a sample that had been collected in South Africa on 5 November. In contrast, hardly two days passed between sampling the first person known to have been infected in Spain and sequencing (see ‘Sequence of events’).
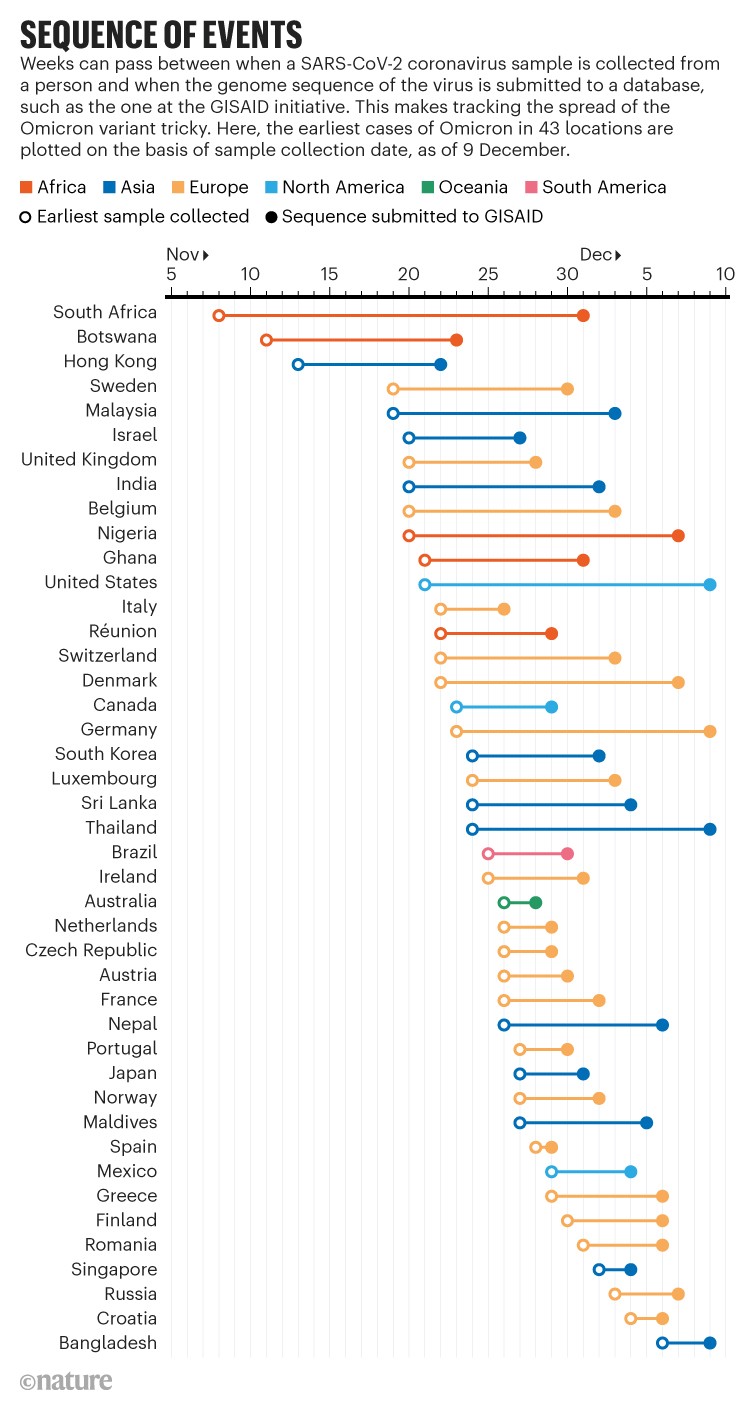
Sources: GISAID and the Pandemic Prevention Institute at the Rockefeller Foundation
Dave Luo, a data scientist who advises Rockefeller’s pandemic institute, warns that this type of timeline can’t alone determine how Omicron is spreading. To do that, scientists must compare the genetic codes of different SARS-CoV-2 sequences, building an evolutionary tree that shows how closely related one virus is to another. Genomic epidemiologists, such as those working on the Nextstrain project, are currently conducting these sorts of analyses.
All of these studies are evolving daily as new Omicron sequences pour in from around the world. A hint of how fast this field is moving can be seen in the rapid rise in genomes reported after the World Health Organization named Omicron a variant of concern on 26 November. Soon after the agency’s announcement, 15 countries submitted 187 genomic sequences belonging to Omicron to GISAID. By 14 December, 55 countries had shared 4,265 Omicron sequences. The figures are on course to balloon further — but Luo warns that’s not necessarily representative of how fast the variant is spreading. Many testing centres are preferentially sequencing samples after a simple, fast genotyping test picks up a possible signal for Omicron — a particular amino acid in the gene for its spike protein. As a result, Omicron might be overrepresented among SARS-CoV-2 genome sequences right now.
Genomic information is biased and messy in so many ways, Luo says. “We have to be careful about what we take away from any one source of data.”
The Link LonkDecember 16, 2021 at 11:45PM
https://www.nature.com/articles/d41586-021-03698-7
Omicron blindspots: why it's hard to track coronavirus variants - Nature.com
https://news.google.com/search?q=hard&hl=en-US&gl=US&ceid=US:en

No comments:
Post a Comment